Presentations
I always enjoy giving presentations about my research and other activities. I try to make the presentation materials available whenever possible. You'll find links to most of my talks below.
October 13, 2016
4:00pm

(Invited Guest Lecture)
Data In Nuclear Engineering
Informatics 500 Seminar
Urbana, IL
This talk gave an overview of the origin, evaluation, processing, and validation of data in nuclear engineering. In particular, it highlighted the variability of cross section data, the nuclear structure they attempt to capture, and real concerns related to compensating errors within current evaluated nuclear data sets. This draws on a talk by Morgan C. White concerning what he terms 'the data dilemma.'
August 27, 2016
(Invited Keynote)
Human Learning at Scale
PyData Conference
Chicago, IL
Today's researchers and future researchers are in great need of a new kind of curriculum, but delivering that curriculum at scale is a mounting challenge. I'll discuss how a data-intensive computational world calls for data-intensive computational education at every level (including children, high-schoolers, college students, researchers, emeritus professors). This talk will touch on how my understanding of this need is informed by my own experience as well as work conducted with the Moore-Sloan Reproducibility and Open Science Working Groups at UW, NYU, and UCB. This talk will touch on attempts at many scales to meet the challenge at hand. These will include both failed and successful efforts by myself, my colleagues, organizations such as The Hacker Within and Software Carpentry, and it will also touch on the important contributions of the open source python community. Finally, I'll share a glimpse of my newest and most real challenges inserting data intensive computational workflows into traditional engineering curriculum.
June 19, 2016
(Invited Participant)
Engineering Academic Software
Engineering Academic Software Dagstuhl Perspectives Workshop
Schloss-Dagstuhl, GERMANY
Software is at the heart of modern academic science, but our institutions for education and research are undergoing growing pains concerning the proper care and feeding of software and software developers in the context of academia. Conducting open, reproducible, computational science in the domains involves many practical challenges. Leading a software-development-focused research group in academia can be difficult to fund and manage with traditional strategies. Similarly, programs for training students in the domain sciences to become effective computational researchers are rare, immature, untested, or untennable. Research leaders are also faced with challenges in software sustainability and are unprepared to develop the user-developer communities needed to sustain and improve their software in their scientific domain. Finally, efforts to improve the quality of scientific software through top-down pressure are hampered by publication venues (journals, etc.) hesitant to adopt and uphold stricter software quality requirements. Software Carpentry, Lab Carpentry, The Hacker Within, and other initiatives are currently lowering the barriers for academics who produce software as part of their research work. However, more effort is needed to support a new generation of computationally fluent research teams.
May 27, 2016
11:00am

(Lightning Talk)
BIDS: Berkeley Institute for Data Science
Nuclear Data Science Workshop - Sorma West
University of California, Berkeley, CA
A discussion of the various eductional activities at the Berkeley Institute for Data Science and at Berkeley more generally
May 3, 2016

(Invited Keynote)
Reproducibility Initiatives at the Berkeley Institute for Data Science
NYU Reproducibility Symposium
Brooklyn, NY
In parallel with the Moore-Sloan Data Science Environments at UW and NYU, the Berkeley Institute for Data Science (BIDS) has a working group focused on Reproducibility and Open Science. This working group has hosted workshops, horizon scans, tutorials, and seminars at Berkeley to encourage discussion, identify needs, and assist scientists with adopting available reproducibility tools. We are engaged in numerous projects related to these efforts. One is the development of a book of "reproducible case studies" that we collected from scientists across institutions and scientific disciplines. Each case study is a collection of a researcher’s summary of their most reproducible workflow, their insights about the tools used, the distinct stages of the workflow, the difficulties encountered while making the project more reproducible or replicable, and finally, any noteworthy benefits realized from the use of specific tools or research strategies. The book is intended to be a resource for scientists seeking to learn about potential best practices and processes that they might use toward reproducibility in their own work. This talk will review what we discovered through this process, including insights about researcher workflows, pain points, incentives, and human challenges.
March 3, 2016
11:00am

(Seminar)
Progress on Coupled Physics Modeling in Fluoride Salt Cooled High Temperature Reactors
RPNSD
Oak Ridge National Laboratory
This talk will discuss progress using various approaches to coupled physics analysis of reactor transients in Fluoride Salt Cooled High Temperature Reactors (FHRs), with particular focus on the Pebble-Bed, Fluoride Salt Cooled, High Temperature Reactor (PB-FHR). These have evolved from algebraic and 0-D models to more comprehensive 3D models. Development of steady state benchmarks for FHR simulation will be touched upon, as will challenges encountered in conducting benchmark comparisons among software of differing capabilities in this arena. The development and implementation of an incompressible but thermally expandable model of salt flow through the pebble bed will be discussed as well, in the context of implementation within the MOOSE framework.
March 2, 2016
1:30-2:30pm

(Invited)
Reproducible Approaches to Modeling and Simulation in Nuclear Energy
Nuclear Engineering Department Colloquium
University of Tennesee, Knoxville
The world's energy future depends on improved safety and sustainability of nuclear reactor designs and fuel cycle strategies. Insights can be drawn from numerical experiments that model and simulate these systems. Both reactor and nuclear fuel cycle dynamics are sufficiently complex that sophisticated scientific software methods, high-performance computing resources, and data analysis algorithms are essential to improving our understanding of them. Furthermore, improved reproducibility and verification in these numerical experiments can be achieved through judicious use of scientific computing best practices. This talk will touch on best practices approaches to building software and simulations for coupled physics analysis of reactor transients in the Pebble-Bed, Fluoride Salt Cooled, High Temperature Reactor (PB-FHR) as well as Cyclus, the agent-based nuclear fuel cycle simulation framework.
November 15, 2015
2:00pm
(Keynote)
A Pythonic Future for Science Education
Supercomputing Conference, Workshop on Python For High Performance Computing
Austin, TX
Detailed computational models, massively parallelized calculations, and enormously collaborative simulation projects are increasingly integral to the advancement of science. However, the caliber of this work is limited by a workforce lacking formal training in essential software development skills. To address this unmet need, a number of initiatives (e.g. Software Carpentry, Data Carpentry) have developed online resources and led short courses addressing software development best practices such as version control and test driven code development, as well as basic skills such as UNIX mobility. With the exception of the Software Carpentry Drivers License for High Performance Computing, however, these initiatives stop just shy of parallelization concepts and skills, and their scalability and sustainability is further limited by the volunteer power on which they run. The challenge at hand will only be sustainably solved when best practices in research-grade scientific computing have penetrated the traditional science and engineering curriculum in universities. This talk will describe a new effort to embed best practices for reproducible, application-focused, research-grade scientific computing into traditional university curriculum. In particular, a set of open source, liberally licensed, IPython (now Jupyter) notebooks are being developed and tested to accompany a book “Effective Computation in Physics: A Field Guide to Research in Python.” These interactive lecture materials lay out in-class exercises for a project-driven university course and are accordingly intended to be forked, modified and reused by professors across universities and disciplines. With Python as a teaching language, this course prepares university students for research at scale by approaching practical scientific computing challenges such as data structures, performant simulation design, hierarchical data storage, parallelization, analysis, and visualization.
November 6, 2015
11:00am

(Colloquium)
A Computational Future For Science Education
National Center for Supercomputing Applications
University of Illinois, Urbana, IL
Detailed computational models, massively parallelized calculations, and enormously collaborative simulation projects are increasingly integral to the advancement of science. However, the caliber of this work is limited by a workforce lacking formal training in a reproducible, transparent, software development skill suite that is becoming increasingly essential. To address this unmet need, a number of initiatives (e.g. Software Carpentry, Data Carpentry, and The Hacker Within) have developed online resources, led short courses, and nurtured local communities addressing software development best practices such as version control and test driven code development, as well as basic skills such as UNIX mobility. In addition to unique contributions such as a Drivers License for High Performance Computing, Software Carpentry conducts workshops at research institutions around the world. These workshops seek to provide time efficient introductions to essential programming languages and tools without turning “biochemists and mechanical engineers into computer scientists”. The Hacker Within similarly nurtures a peer-driven community for scientific computing skill sharing. It does so through regular meetings in a few local chapters around the world, including one at the University of Illinois. The scalability and sustainability of these initiatives, however, is limited by the volunteer power on which they run, so their challenge will only be sustainably solved when best practices in scientific computing have penetrated the traditional science and engineering curriculum in universities. This talk will describe one new effort to embed best practices for reproducible scientific computing into traditional university curriculum. In particular, a set of open source, liberally licensed, IPython (now Jupyter) notebooks are being developed and tested to accompany a book “Effective Computation in Physics.” These interactive lecture materials lay out in-class exercises for a project-driven upper-level undergraduate course and are accordingly intended to be forked, modified and reused by professors across universities and disciplines.
October 3, 2013

(Conference Presentation)
Cyclus Fuel Cycle Simulation Capabilities with the Cyder Disposal System Model
American Nuclear Society Conference
Salt Lake City, UT
Presentation concerning the Cyder disposal system model built for the Cyclus tool.
March 1, 2011

(Poster)
Cyclus: An Open, Modular, Next Generation Fuel Cycle Simulator Platform
Waste Management Symposium
Phoenix, AZ
poster concerning Cyclus open next generation fuel cycle simulator.
June 2008

(Seminar)
Consolidated Fuel Treatment Center and Advanced Burner Reactor
University of Chicago Big Problems Energy Analysis Course
Chicago, IL
August 2004
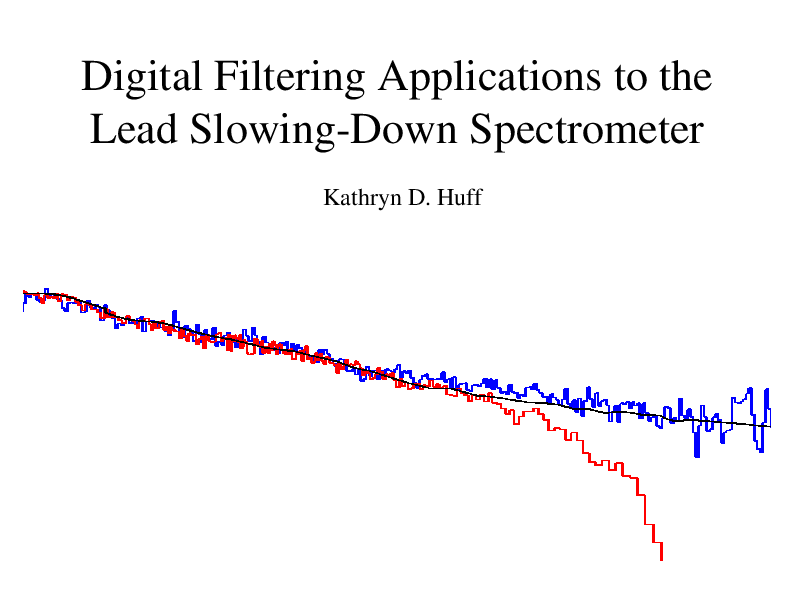
(REU Summer Seminar)
Digital Filtering Applications to the Lead Slowing Down Spectrometer
Los Alamos Neutron Science Center (LANSCE-3)
Los Alamos, NM
Digital filtration application to the signal from the LSDS at LANSCE-3.
August 2003
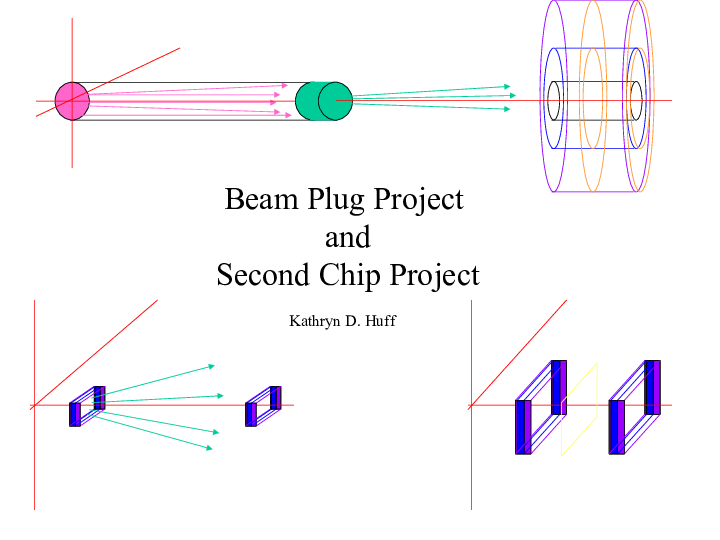
(REU Summer Seminar)
Beam Plug Project and Second Chip Project
Los Alamos Neutron Science Center (LANSCE-3)
Los Alamos, NM
A project concerning the necessary size of beam plug in the fictional scenario of an uncontrollable accelerator at LANSCE.